Searching for and Opening Files in AWS S3 Buckets - Part 5 of 5


In this fifth part of the series, (Part One | Part Two | Part Three | Part Four) I describe how to search for and open files in AWS S3 buckets. Like many things in cloud engineering and frankly, AWS in general, it turns out that a topic which should be simple has a few major gotchas. I cover them here before explaining why columnar file formats like Apache Parquet are such a big deal for data engineering and therefore data security.
As with all of these posts, they are unapologetically focused on AWS S3, the unbounded data storage behind data warehouses and data lakes. The rationale is simple: this is where you are almost guaranteed to find the crown jewels and it’s the first port of call for attackers.
Note: In this post I use the terms ‘object’ and ‘file’ interchangeably as the former is AWS S3’s term, but I suspect most in the security industry will be more familiar with the latter.
In Part Three I showed you how to get the list of all of your buckets and how to pull basic security configuration information about those buckets so that you can prioritize which ones to examine. The natural and obvious thing to want to do when you have that list is to say “let's examine all the files in all the buckets,” or “all the things” as one of our developers says. We get it, we really do but in reality it's just not practical. AWS S3 is unbounded storage meaning you can store as many files with as much data as you want, and with that level of flexibility means that users often have buckets that contain millions of files and petabytes of data. Extrapolate that across a company and you will find that you would be trying to scan billions of files and exabytes of data. We tried and got up to 220 billion files before the inevitable slack emoji of a boat was sent along with a message “we are gonna need a bigger boat”. Among other things, the elastic search index only goes to a trillion.
We like to think that if anyone could scan unbounded storage it would be us with the Lambda scanning model, but even if we could you wouldn’t want to. First, you simply won’t know when a scan will complete. Even with elastic computing it is almost definitely not before the data has changed or you have got bored waiting, make your selection. The second reason is cost. While elastic computing is cheap, it is never free and when you start to deal with true scale even tiny billing increments become big sums fast.
What you need to do is to be selective, much like you have already done with buckets, and the first step in being selective is to decide what type of files you want to scan. Luckily, AWS provides an API to list the bucket objects. Unluckily, it's a PITA to use and you have to do a lot of hoop jumpery to get what you need.
Returns some or all (up to 1,000) of the objects in a bucket with each request. You can use the request parameters as selection criteria to return a subset of the objects in a bucket. A 200 OK response can contain valid or invalid XML. Make sure to design your application to parse the contents of the response and handle it appropriately. Objects are returned sorted in an ascending order of the respective key names in the list. For more information about listing objects, see Listing object keys programmatically
private void discoverS3BucketObjects(S3Client client, Bucket resource) {
var objectListing = client.listObjectsV2Paginator(ListObjectsV2Request
.builder()
.bucket(resource.name())
.maxKeys(1000)
.build());
objectListing.stream()
.flatMap(r -> r.contents().stream())
.forEach(content -> System.out.println(" Key: " + content.key() + " size = " + content.size()));
}
And guess what? After all that hoop jumpery, the list of objects are almost useless until you do further analysis. While using object extensions like .txt and .parquet are the polite way to read / write files they are far from the only way.
The first important thing that we have seen in the field is that as many as 50% of objects in buckets have no file extension at all. Yes, 50% and a large range from small to massive and after examination, a large range of actual objects.
The second important thing that we have seen in the field is that developers like to use their own file extensions or rename standard ones. Yes, payroll.mark can be a zip file and bigdata.log can actually be a JSON file.
So, rather than relying on the file extension to understand the contents (and thus how to parse/process it – see later), one must identify the mime-type (aka content-type) of the file.
Some clients (webbrowser, Java, etc.) can detect and set the content-type automatically during upload, so even if you upload payroll.mark and the client understands it to be a text file, it will add “content-type: text/plain” to the upload. However, the content-type can be overridden during upload, or in other cases still, the content-type is unknown to the client, so it can be set to something generic, like ‘binary/octet-stream’.
What this means is that you need to do what is referred to as MIME sniffing, or content sniffing, to determine what the object actually is. MIME sniffing is common in web technology and means opening each file and parsing the file header to determine what the file actually is. We do this mainly using the excellent Apache Tika library.
private void discoverObjectMimeType(S3Client client, Bucket resource, String objectKey){
TikaConfig tika = new TikaConfig();
var objectContentsStream = client.getObject(GetObjectRequest
.builder()
.bucket(resource.name())
.key(objectKey)
.build());
Metadata metadata = new Metadata();
metadata.add(Metadata.RESOURCE_NAME_KEY, objectkey);
String mimetype = tika.getDetector().detect(TikaInputStream.get(objectContentsStream), metadata);
System.out.println(String.format("Detected %s as mime-type", mimetype));
}
At this point we have the necessary pieces of the puzzle because we can:
- connect to an AWS org
- list all the accounts in the AWS org
- list all the resources in each account and select the AWS S3 buckets
- select the S3 buckets of interest
- list the objects in those buckets
- MIME type sniff all the objects in that list
- build the list of the objects on which to perform data classification
Of course, in an ideal world you would list all of the objects, MIME type sniff all the objects and then apply your selection criteria i.e., only files of type x, y and z. But, this has the scalability problem of needing to open every object and stream in enough data to perform MIME type sniffing, which may be the entire file. Chicken and the egg...
As I mentioned in the first post, we have learned a lot in the field and continue to do so and there is a long list of debug stories.
A recent example was a customer support ticket about a reporting discrepancy when compared with AWS: We reported that the bucket contained over a hundred thousand files but when looking in the AWS console, it only showed one. A bug? No, it turns out the AWS console doesn't show hidden folders and if you have automatic access logging turned on, it is routed to its own logs directory.
"BucketLoggingConfiguration" : {
"loggingEnabled" : {
"targetBucket" : "bucket-name",
"targetGrants" : [ ],
"targetPrefix" : "/logs"
}
},
This means every access would generate a new log entry in that logs directory.
To wrap this post up I want to explain what Apache Parquet is, why it is such a big deal for the data engineering world and therefore such a big deal to the data security world.
Parquet is an open source columnar file format. https://parquet.apache.org/ that is optimized for query performance and minimizing I/O i.e designed specifically for big data.
Row oriented databases and files are systems that organize data by record, keeping all of the data associated with a record next to each other.
Example databases are PostGres and MySQL and file formats like .CSV and .XLS.
Column oriented databases and files are databases that organize data by field, keeping all of the data associated with a field next to each other.
Example databases are RedShift, BigQuery and SnowFlake and file formats like Apache Parquet.
This is an excellent example that illustrates the difference from the AWS RedShift documentation.
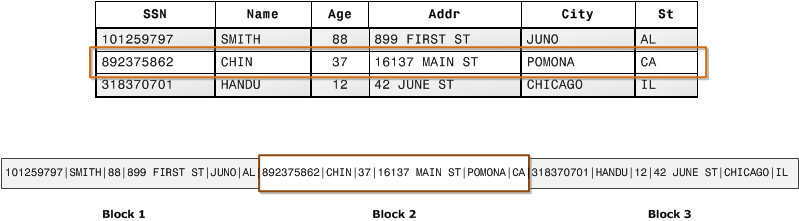
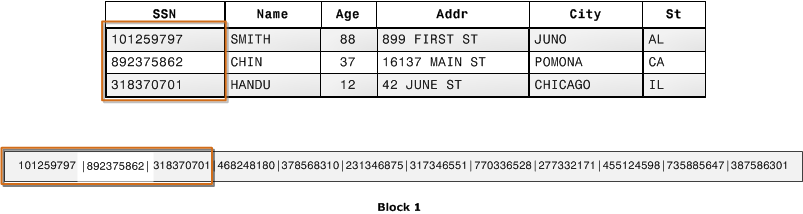
As a general rule of thumb, row oriented formats perform best for the operations on the whole row and columnar for the operations on the columns. Where row orientated operations like Add/Delete/Update whole row, column oriented operations like aggregations work on the columns only. Given block operations are one of the biggest contributors to performance, columnar formats can optimize space as they keep homogenous data in a single block and apply strategies to compress the data in a block. This results in less fragmentation and faster reads because there are fewer blocks to read as well as much smaller files, and much smaller files means less costs.
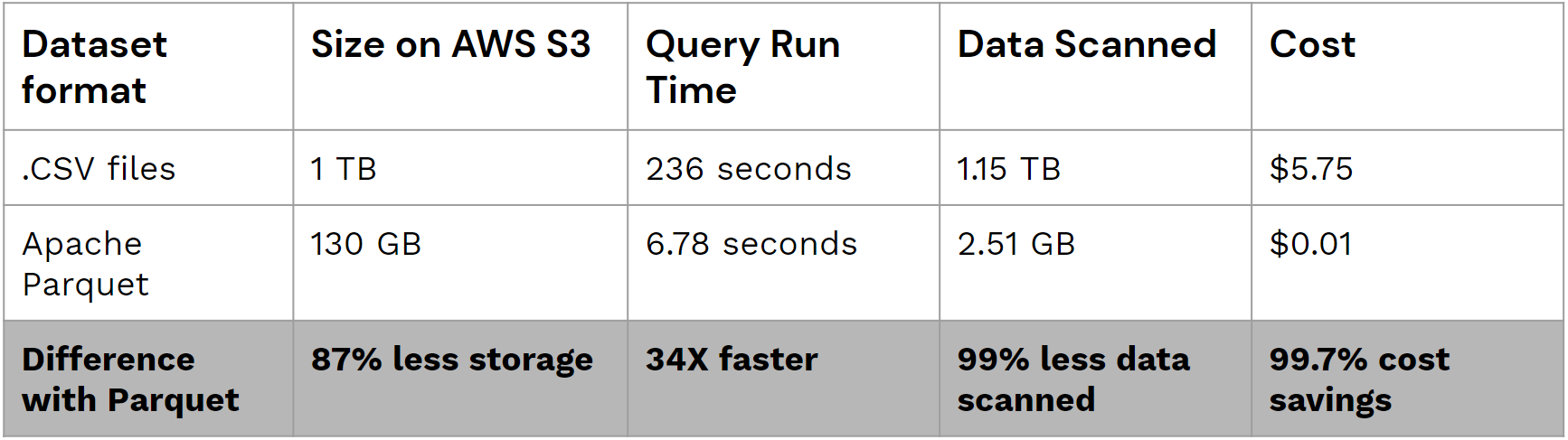
Cheaper and faster. Here is a simple chart showing the cost and speed difference in storing data in .CSV versus Parquet, courtesy of the DataBricks site.
In the next post in the series called Practical classification techniques, I will be describing pattern matching (regexes and machine learning), data adjacency and data validation.
References
https://dataschool.com/data-modeling-101/row-vs-column-oriented-databases/
https://blog.openbridge.com/how-to-be-a-hero-with-powerful-parquet-google-and-amazon-f2ae0f35ee04
https://databricks.com/glossary/what-is-parquet
https://docs.aws.amazon.com/redshift/latest/dg/c_columnar_storage_disk_mem_mgmnt.html



