Operationalizing Data Security in the Cloud at Scale - Data Security Rules Explained Part 1


“Ok, I can see the data now, but what do I do with it?”
These were the words of a security leader after inventorying and classifying data in the cloud. As an industry, we’ve done it so infrequently that we have no real muscle memory to indicate what the obvious next step is after we gain visibility into our data. We’ve found that in order to operationalize data security, visibility isn’t enough. The knowledge of where sensitive data resides has to be coupled with a generous amount of context before it has enough meaning to compel someone to take action.
This isn’t a new problem. DLP alerts were notoriously vague and required skilled analysts to determine what events were meaningful and what wasn’t. One of the early stories we heard was about a Fortune 100 company who had a larger support staff for a DLP product than the DLP vendor had itself. This would never fly in the hyperscale, automation-driven world of the public cloud.
The aim of this blog series is to explain what we’ve found that works for creating actionable alerts for cloud data security. The recipe for operationalizing data security in the cloud at scale includes the following ingredients:
- Data Classification - to identify sensitive data
- Data Context - to identify the precise conditions that matter for the data itself
- Rules / Rules Engine - to define what conditions we want to test for by matching data and context, which then in turn create…
- Alerts - the time-honored security event that we know how to feed into existing workflows & response tooling; more necessary than beloved
- Policies - to group both rules and alerts together
Before we explore each one of these, I owe you an example of what a “good” alert looks like. If it’s not “You have a misconfigured AWS S3 bucket!”, what is it exactly?
It could be “You have AWS Secret keys on the 1114th line of file.json in an S3 bucket that’s exposed to the Internet”.
Or “Your PCI DSS scope just expanded due to payment cards being discovered in a new VPC in US East (Ohio).”
In short, knowing about sensitive data is great. Infrastructure and other context is nice. Just like peanut butter and chocolate, the two are better together and produce alerts that are precise, meaningful and actionable. But sadly not delicious.
Data Classification
I’m going to keep this one brief since we’ve covered it in-depth in many other posts, but if you don’t know what data you’re trying to protect it’s awfully hard to know where to focus. You end up treating everything equally or making dangerous assumptions about what data lives where. Go back to any of a number of recent cloud data leaks and I’ll bet you the poor person embroiled in the incident would tell you “That data wasn’t supposed to be there.” Being proactive about locating and discovering sensitive data greatly reduces the risk of accidental data leaks. Sometimes simply seeing shadow or clearly toxic data is enough to know that it needs to be dealt with, most times it’s just a solid first step.
Context
So what’s meant by context? This is the environmental information around the data itself that you would typically get from a CSPM (which would not be able to match it to the sensitive data).
It’s knowing the data store that the data resides in and its exact location, from account to VPC to region.
It’s the network settings for where the data resides, such as security groups and peering relationships.
It’s knowing how the data store is configured and especially its security attributes, from Internet accessibility and use of encryption to versioning and use of MFA.
It also can be where, when and how the data is backed up.
Or who has access to the data itself.
And so on.
When combined with knowledge of sensitive data from classification, you can create very precise alerts for specific data risk conditions that matter to your organization. It could be anything from tracking the data related to a critical project with a partner for safety or enforcing a strict protection standard for a certain class of data.
This context is built using native APIs and at times doing basic analysis with serverless functions (e.g., AWS Lambda).
So what is data context? It's the insights into locations of sensitive data from classification. It's the critical element that CSPMs can't provide. When you add data context to resource configuration settings you can create precise alerts for specific data risk conditions.
Rules / Rules Engine
Rules are the statements that harness the results of data classification and context building to test an environment for a specific condition or state. The rules engine is what executes the code in those statements in order to determine if an alert (or policy violation) should be created.
In the early days of Open Raven, we began using Open Policy Agent (OPA) and wrote a large number of rules in its native language called Rego. Rego is known for being context-aware, declarative, and portable across a number of backends and data. This made easy work of querying asset configurations which were stored as JSON blobs in PostgreSQL.
Rego’s shortcomings became readily apparent when we attempted to write more complex security rules. Rego didn’t allow us to create rules that spanned more than a single asset type. For example: an EC2 Instance with a public IP and a security group allowing access from 0.0.0.0/0.
Following our experience with OPA, we moved on to a new approach that allows us to write rules in both SQL and Python. The combination of both has given us the flexibility we were after to easily write simple rules as well as the power to write more complex rules with a full-blooded programming language like Python. Thus far, we’ve found most rules can be readily expressed in SQL. This has the added benefit of lowering the bar for customers and partners to be able to create their own rules without having to learn a new language or even write code.
Here’s an example of the rule “Health care data is not encrypted at rest”:
SELECT s3scanfinding.assetid,
s3scanfinding.scantarget,
s3scanfinding.scantargetchild,
s3scanfinding.findingscount as count,
s3scanfinding.dataclassid
FROM s3scanfinding INNER JOIN awss3bucket ON s3scanfinding.assetid = awss3bucket.arn INNER JOIN dataclass ON dataclass.id = s3scanfinding.dataclassid INNER JOIN datacollection_dataclass ON dataclass.id = datacollection_dataclass.dataclassid WHERE datacollection_dataclass.datacollectionid = '0c949d94-00ae-4d24-8306-0d866b644514'
AND awss3bucket.supplementaryconfiguration -> 'ServerSideEncryptionConfiguration' ->> 'rules' IS NULL
The SELECT statement is pulling out the relevant values about scan findings (Open Raven Dataclasses) and performing an inner join against all discovered S3 buckets where its supplementaryConfiguration field (JSON blob) has ServerSideEncryptionConfiguration set to null. Where the assetid’s match is a bucket in violation of this rule.
The UUID contains the identifier for the Dataclass in question (healthcare data).
This rule could be easily extended to specify more configuration requirements, made specific to a region, indicate a particular data storage type, etc.
Alerts
Rules that trigger create alerts that possess all the details in a single place in order to make remediation straightforward. Here’s what an alert looks like in Slack:

Following the link would bring you to the gory details which would look like this, taking you all the way down to the file itself with the exposed data.
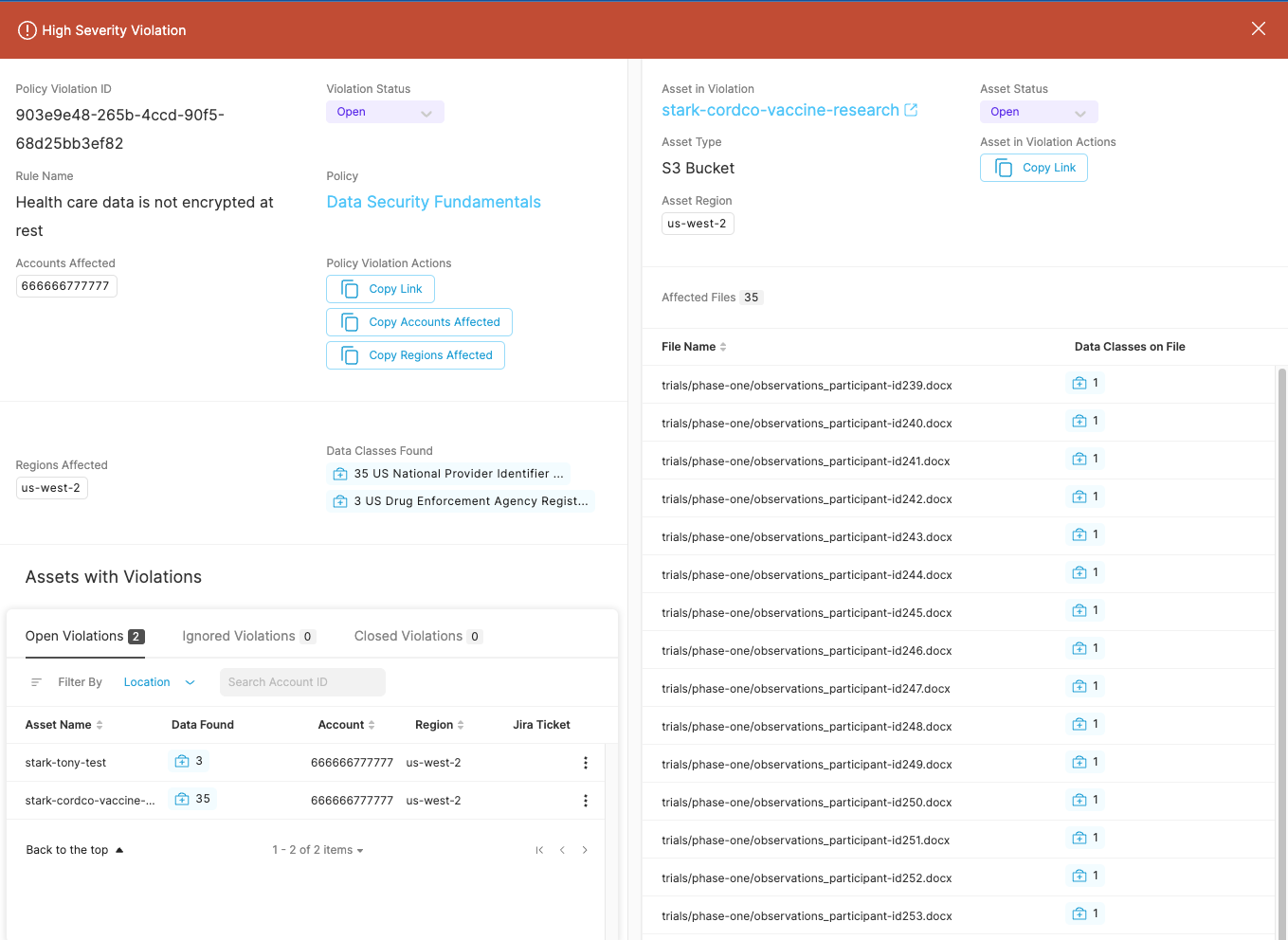
From here, you can go straight to the AWS Console via deeplinking, create a Jira ticket or more. And of course you can auto-process and respond to alerts as well.
Policies
We’ll wrap up with the easiest: policies are just collections of rules. It could be anything from a CIS Benchmark to an Open Raven Data Security Basics or a custom policy designed to monitor for any of a number of issues.
Recap & Next up
To recap, operationalizing data classification takes a healthy amount of context which are combined inside of rules which are used to trigger precise alerts that can be processed manually or automatically. The idea here is to keep alerts to minimum by making them incredibly specific to solely the things that matter the most. By doing this, you can spend a few minutes in triaging an alert versus hours or days cleaning up after an incident.
In the next blog in this post we’ll take a safari through a series of data security rules to give a better sense of what we’ve done inside the platform and what’s possible.



